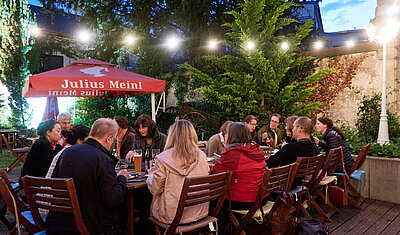Summaries of previous meetings of the IUNTC
Contents
Topic | Author: | Read full article: |
| How to Use Use-Lab's Methods in Assessments | Stephanie Schwenke (Project manager at Use-Lab GmbH) | Read |
| Introducing Technical Communication into a Cooperative Study Program | Kathrin Reinhard (Leading the user documentation team at Siemens Healthineers AG’s) | Read |
| AI-Enabled Technical Content Delivery – Impulses for Technical Communication | Kees van Mansom (Technical Publication Services Lead Europe, Accenture) | Read |
| FAIRTterm 2.0: A Web Application for FAIR Terminology Management | Federica Vezzani (University of Padova, Italy) | Read |
| Information Mapping: How Structure Enables Better Content, Safer AI, and Smarter Decisions | Stephanie De Waegenaere (Senior Growth Manager, Information Mapping) | |
| How Projects Propel TC Learning to New Heights | Prof. May Li (MA/PhD, University of Manchester) | Read |
| The Human Factor in Technical Communication | Roxana Blăgescu (Executive, Leadership, and Communication Coach) | Read |
Enhancing Health Literacy through Controlled Natural Languages | Federica Vezzani (University of Padova, Italy) | Read |
| Composing with Generative AI in TechComm: Insights from Digital Marketing | Daniel L. Hocutt (University of Richmond) | Read |
| Status of the new EU legislation what information is relevant for technical writers? | Susanne Akdut (Technical Writer and Certification Expert) | Read |
| AI-based IIRDS tagging of technical documents | Gerald A. Zwettler (University of Applied Sciences Upper Austria) | |
Artificial Intelligence Literacy and Adjacent Digital Literacies for the Digitalised and Datafied Language Industry | Prof. Dr. Ralph Krüger (Institute of Translation and Multilingual Communication at TH Köln) | Read |
| A framework for understanding cognitive biases in technical communication | Prof. Dr. Quan Zhou (Metropolitan State University) | Read |
| The Process Is Not the Job: A Technical Writer's Journey in a Regulated Industry - Improving Technical Writing in Regulated Industries | Gianni Angelini (Technical Writer) | Read |
Empirial studies in translation and interpreting: an overview | Dr Caiwen Wang (Senior Lecturer in Translation and Interpreting Studies in the School of Humanities of the University of Westminster and an Associate Professor in Translation and Interpreting at the Centre for Translation Studies of UCL, UK) | |
AI in practise | Claudia Sistig (Graduate of the Technical Writing program at Hochschule Hannover) | Read |
| Human augmentation in Technical Communication in the world of AI | Nupoor Ranade (Assistant Professor of English at George Mason University) | Read |
Insights into user assistance development at SAP | Dominik Strauß (from SAP) | |
Introducing iiRDS to Universities: Gain insights and get involved | Ralf Robers (head of the documentation department at Körber Supply Chain Logistics GmbH) | Read |
| What does ChatGPT mean for teaching technical communication? | EAC (International Network of Universities in Technical Communication) | Read |
| What are the new ways of working for technical communicators? | Kai Weber (Technical Writer for financial and banking software) | Read |
| How to integrate research into the TC curriculum: an experience report and some lessons learned | Prof. Dr. Michael Meng (Professor of Applied Linguistics at the University of Merseburg) | Read |
| Master’s in Communication and Media: Introduction of a New Study Discipline at Pwani University in Kenya | Professor Sissi Closs and Belinda Oechsler (University of Applied Sciences, Karlsruhe (HKA) | Read |
| Technical Communication Teaching Projects: Virtual Exchanges with the TAPP Project | Suvi Isohella (University of Vaasa in Finland) | Read |
| How do YOU search for existing knowledge? IUNTC Meeting Explores Search Strategies in Technical Communication | Dr. Kim Sydow Campbell (Professor of Technical Communication at the University of North Texas, USA) | Read |
| How important is localizing user documentation? | Dr. Joyce Karreman (Assistant Professor of Technical Communication at the University of Twente in the Netherlands) | Read |
| Trends and demands in specialized technical communication | Dr. Christiane Zehrer (Certified Scrum Master and a technical communication instructor at Hochschule Magdeburg-Stendal) | Read |
What does ChatGPT mean for teaching technical communication?
Results from the first in person meeting of the International Network of Universities in Technical Communication
The first in-person meeting of the International Network of Universities in Technical Communication – IUNTC - took place in the late afternoon of May 4 at Karlsruhe University of Applied Sciences, Germany, preceding the European Academic Colloquium (EAC). About 20 people from all over Europe--university teachers, students and people interested in technical communication-- gathered to discuss important topics about studying and teaching technical communication. It was an excellent opportunity for networking, exchanging ideas, finding project partners and getting to know about the latest trends.
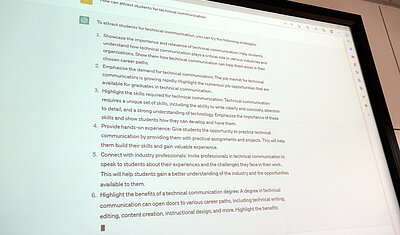
In keeping with the motto for the eighth European Academic Colloquium - the next steps in digital transformation - the question arose as to how ChatGPT will change teaching and learning. Generative AI technologies, such as large language models, have the potential to revolutionize much of our higher education teaching and learning.
May 2023 By Yvonne Cleary & Daniela Straub
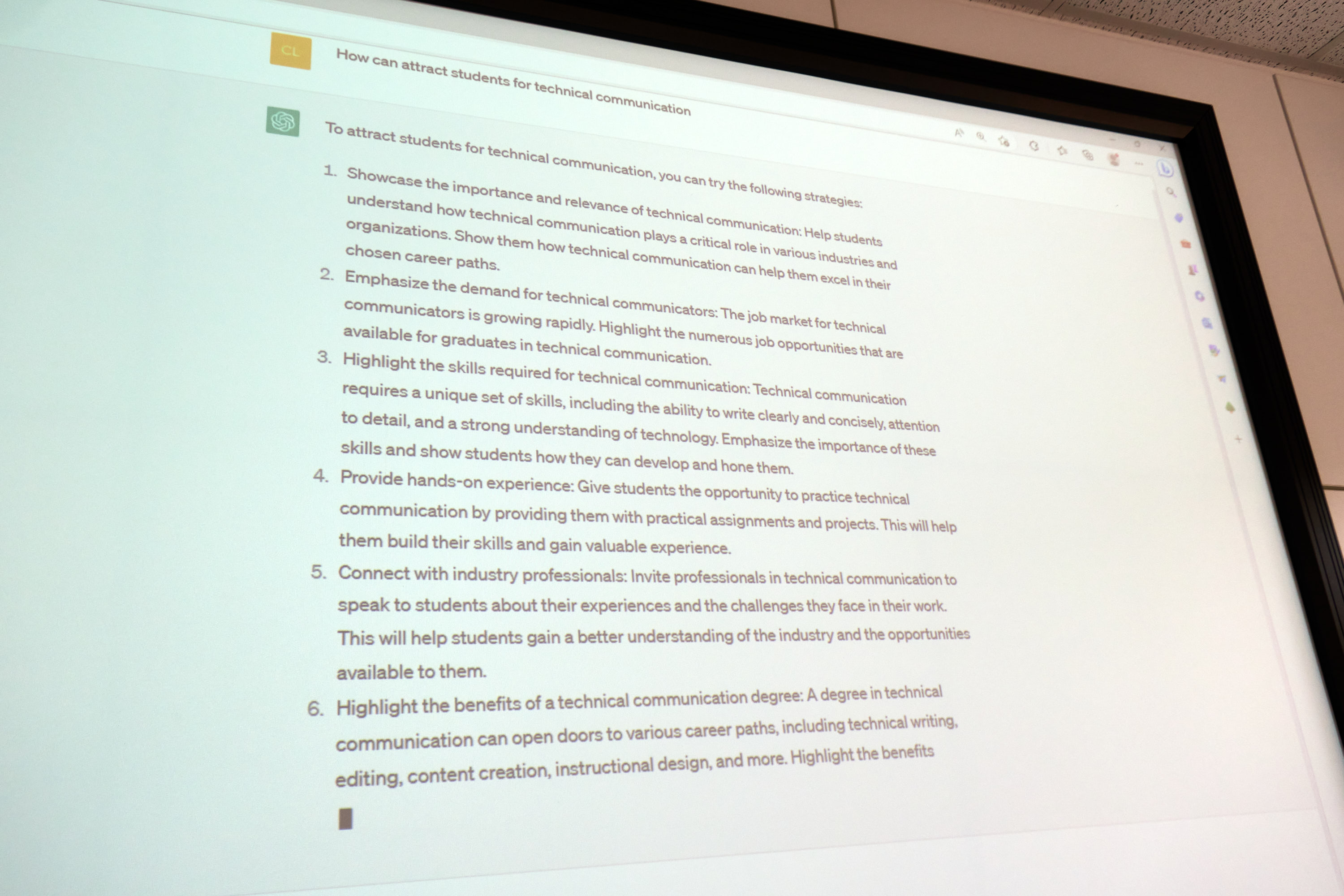
There are many questions to solve, for example from the student‘s perspective, whether they are allowed to use ChatGPT for a seminar or final paper, or whether this practice constitutes cheating? How can they use ChatGPT best? What skills should they acquire, and what skills are obsolete because of ChatGPT? Teachers and lecturers also ask similar questions from a different perspective. They deal with questions like: which skills should be taught and how can students’ competencies be tested rather than their ability to prompt generative AI models. Also, how can ChatGPT and other systems based on generative AI be used to increase the efficiency of developing training, or even improve teaching. Challenges from the teacher‘s side include ensuring students do not simply copy and paste their work from ChatGPT and ensuring that students do not use ChatGPT as a tool for assignments. They have to focus how teaching courses, learning for exams, writing seminar papers and theses, and assessing student learning and performance will change because of the new technology.
In order to improve the participants’ understanding of ChatGPT, we had demonstrations in the meeting. ChatGPT is an artificial intelligence (AI)-based conversational agent that can generate various types of content, including college-level essays. Generative AI systems can generate text, images, or other representations with relatively little human input. They work most effectively when the prompt is precise and specific, so it is really important to formulate a good question, to which ChatGPT then "writes" the answer.
We - the participants of the IUNTC asked ChatGPT if it could write us an opening speech for the following day’s EAC. All participants were amazed at how good the result was. Since this was a vivid experience of how the technologies will also revolutionize technical communication, the group decided to show it at the opening of the EAC - a demonstration of how AI and digitization will change technical communication and teaching.
Hence, it is not surprising that the advent of generative AI fundamentally challenges accepted knowledge, assumptions, and behaviors in higher education. And one thing is also obvious: ChatGPT and GPT-4 are only the forerunners of what we can expect from future generative AI-based models and tools. So it is worth looking into the impact on higher education.
The next IUNTC meeting on Wednesday, 7th of June at 3:00 pm will continue to deal with this topic in detail: AI in academia: balancing benefits and challenges by Jenni Virtaluoto & Prof. Sissi Closs.
Another central question during the meeting was: how can we make technical communication more attractive as a field of study for more students? There was a suggestion on this topic from the University of Munich University of Applied Sciences to find project partners in the community for joint marketing campaigns. The problem that too few students are interested in the courses of study is common across several universities. However, it applies not only to technical communication, but also to other courses of study. In spite of the challenge of recruiting students, technical communication graduates are very attractive for the job market and can expect interesting job offers and a good salary. One challenge is that students may be reluctant to take technical subjects that involve a lot of technology. Current topics such as user experience design or information design may be more attractice. For this reason, many universities are adapting the content of their study programs. In addition, technical communication is not very well recognized as a profession in many countries. Targeted recruitment campaigns would have to start here. In addition, the desired target group - school leavers - is not easy to reach. It´s important to leverage social media and create a social media presence and to showcase technical communication’s relevance and importance which can attract more students who might be interested in pursuing a career in this field. Therefore tekom as the professional organisation for technical communication can help attract more students by providing networking opportunities and marketing campaigns.
The IUNTC meeting ended with a nice dinner together at pleasant summer temperatures in a beer garden in Karlsruhe.